















































Вітаю вас на сайті info-comp.ru! сьогодні ми з вами поговоримо про один дуже популярному алгоритмі, який зустрічається в процесі вивчення програмування, – це «сортування бульбашкою», зокрема ми реалізуємо даний алгоритм на мові t-sql.
Відразу хотілося б відзначити, що навіть в класичному програмуванні даний алгоритм сортування більшою мірою є навчальним, тобто. Використовується тільки для вивчення алгоритмів, а в реальній роботі практично не використовується, так як існують більш ефективні алгоритми сортування, і, звичайно ж, в більшості випадків всі вони вже реалізовані і включаються в інструменти програмування.
Якщо говорити щодо програмування баз даних, то алгоритми сортування тут не потрібні, так як мова sql, який використовується для роботи з даними в реляційних базах даних, працює з безліччю, тобто. З таблицями, і стандартом цієї мови визначена інструкція order by, яка і дозволяє сортувати дані в таблицях.
Тому не шукайте якоїсь практичної складової в даній статті, я спробував реалізувати алгоритм «сортування бульбашкою» на t-sql тільки для того, щоб подивитися, як же він буде виглядати на даній мові, тобто заради інтересу)) справа в тому, що прикладів реалізації даного алгоритму на інших мовах повно, а на t-sql таких прикладів немає.
Опис алгоритму «сортування бульбашкою»
Алгоритм складається з повторюваних проходів по сортованому масиву. За кожен прохід елементи послідовно порівнюються попарно і, якщо порядок в парі невірний, виконується обмін елементів.
Проходи по масиву повторюються n-1 раз або до тих пір, поки на черговому проході не виявиться, що обміни більше не потрібні, що означає — масив відсортований.
В результаті кожного проходу на останнє місце в масиві зсувається елемент з максимальним значенням і не враховується при наступному проході, так як дана частина масиву вже відсортована.
Таким чином, після кожного проходу елемент з максимальним значенням в невідсортованої частини масиву ставиться в кінці масиву поруч з максимальним значенням, яке було в попередньому проході, а елемент з найменшим значенням переміщається на одну позицію до початку масиву, і як результат «спливає» до потрібної позиції, як бульбашка у воді — звідси і назва алгоритму.


Реалізація алгоритму «сортування бульбашкою» на t-sql
На а тепер давайте перейдемо до реалізації алгоритму «сортування бульбашкою» на мові t-sql в microsoft sql server.
В якості вихідних даних у мене буде виступати масив чисел, який представлений на зображенні трохи вище, тобто алгоритм нижче виконує ті ж самі дії, що і на gif зображенні.
Для зручності даний алгоритм я оформив у вигляді збереженої процедури bubble_sort.
Весь код я детально прокоментував.
create procedure bubble_sort as begin —таблична змінна для зберігання масиву даних з числами —індекс масиву починається з 0 declare @data_array table (array_index int not null identity(0, 1) primary key, value int not null); — додавання даних в табличну змінну insert into @data_array values (5),(2),(1),(3),(9),(0),(4),(6),(8),(7); —висновок даних до сортування select array_index, value from @data_array; declare @current_element int, —поточний елемент в масиві @amount_elements int, —кількість елементів у масиві @continue_sort bit; — ознака для продовження сортування — змінні для зберігання значень масиву declare @value1 int, @value2 int; —визначаємо кількість елементів в масиві, враховуючи, що він починається з 0 select @amount_elements = count (*) — 1 from @data_array; set @continue_sort = 1; /* @continue_sort = 1 — продовжувати сортування, масив відсортований @continue_sort = 0 — сортування завершена, масив відсортований */ —запуск циклу для проходу по масиву while @continue_sort = 1 begin —відразу відзначаємо, що сортування потрібно завершити, в разі якщо не буде обміну значеннями set @continue_sort = 0; —прохід по масиву починаємо з першого елемента set @current_element = 0; —запуск циклу для порівняння значень масиву в поточному проході while @current_element<@amount_elements begin select @value1 = 0, @value2 = 0; --отримуємо перші значення в масиві select @value1 = value from @data_array where array_index = @current_element; select @value2 = value from @data_array where array_index = @current_element + 1; --порівняння значень --якщо перше значення більше другого, то необхідно поміняти їх місцями if @value1>@value2 begin update @data_array set value = @value2 where array_index = @current_element; update @data_array set value = @value1 where array_index = @current_element + 1; —відбувся обмін значеннями, значить сортування слід продовжувати set @continue_sort = 1; end —рухаємося далі по масиву set @current_element = @current_element + 1; end /* після проходу по масиву в його кінці виявляються відсортовані елементи виключаємо їх, для зменшення кількості интераций (порівнянь) */ set @amount_elements = @amount_elements — 1; end —вивід даних після сортування select array_index, value from @data_array; end go
Щоб перевірити роботу алгоритму, викликаємо процедуру bubble_sort.
exec bubble_sort;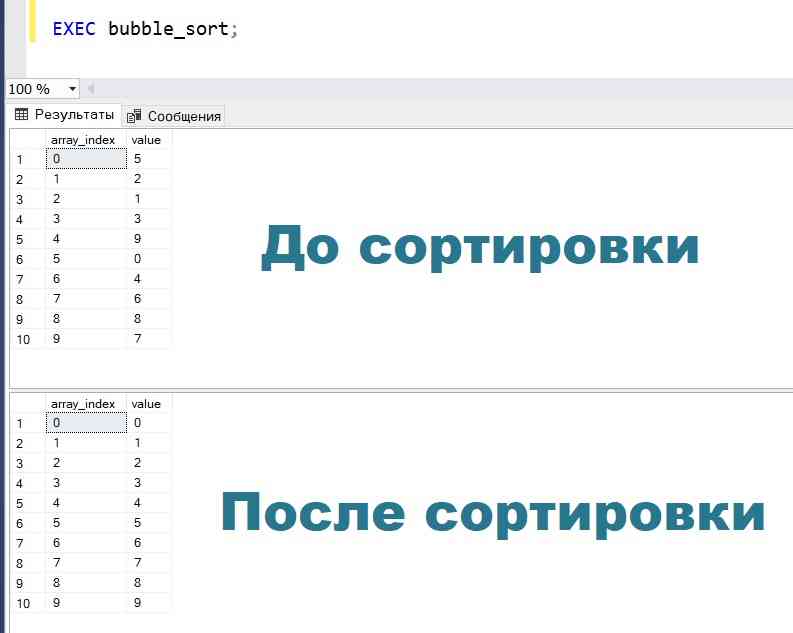
Як бачимо, дані відсортовані.














{kind=link}